FaceTalk: Audio-Driven Motion Diffusion
for Neural Parametric Head Models
1Technical University of Munich
2Max Planck Institute for Intelligent Systems
3Technical University of Darmstadt
Play With Audio
Given input speech signal, we propose a diffusion-based approach to synthesize high-quality and temporally consistent 3D motion sequences of high-fidelity human heads as neural parametric head models. Our method can generate a high fidelity expressions (including wrinkles and eye blinks) and can synthesize temporally synchronized mouth motion for different audio signals like songs and foreign languages.
Abstract
We introduce FaceTalk, a novel generative approach designed for synthesizing high-fidelity 3D motion sequences of talking human heads from input audio signal. To capture the expressive, detailed nature of human heads, including hair, ears, and finer-scale eye movements, we propose to couple speech signal with the latent space of neural parametric head models to create high-fidelity, temporally coherent motion sequences. We propose a new latent diffusion model for this task, operating in the expression space of neural parametric head models, to synthesize audio-driven realistic head sequences. In the absence of a dataset with corresponding NPHM expressions to audio, we optimize for these correspondences to produce a dataset of temporally-optimized NPHM expressions fit to audio-video recordings of people talking. To the best of our knowledge, this is the first work to propose a generative approach for realistic and high-quality motion synthesis of volumetric human heads, representing a significant advancement in the field of audio-driven 3D animation. Notably, our approach stands out in its ability to generate plausible motion sequences that can produce high-fidelity head animation coupled with the NPHM shape space. Our experimental results substantiate the effectiveness of FaceTalk, consistently achieving superior and visually natural motion, encompassing diverse facial expressions and styles, outperforming existing methods by 75% in perceptual user study evaluation.
Video
Results
Sound On
(C) Foreign Languages
(a) German
(b) French
(c) Italian
(d) Chinese
(e) Hindi
Method Overview
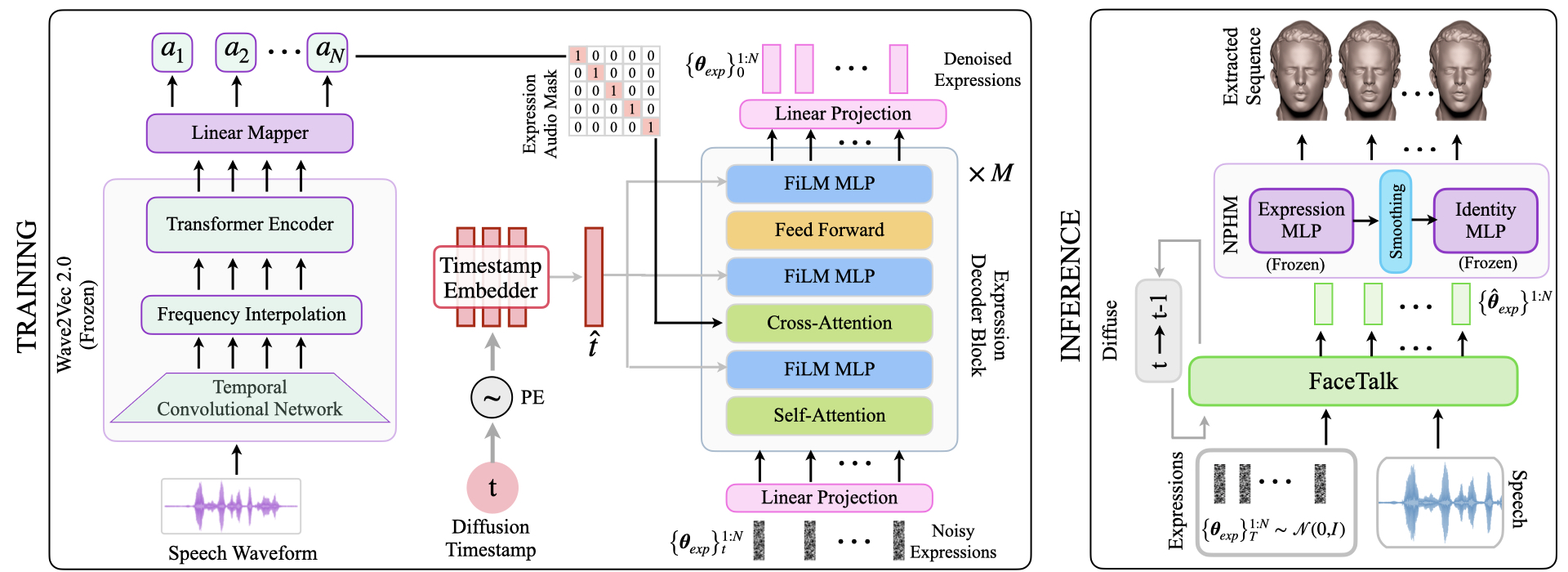
FaceTalk uses Wave2Vec 2.0 to extract audio embeddings from a speech signal. The diffusion timestamp is embedded using a PE (positional encoding) and timestamp MLP (multi-layer perceptron). The expression decoder employs a multi-head transformer decoder with FiLM (Feature-wise Linear Modulation) layers, interleaved between Self-Attention, Cross Attention, and FeedForward layers, to incorporate the diffusion timestamp. During training, the model is trained to denoise the noisy expression sequences from timestamp \(t\). At inference, FaceTalk denoises the Gaussian noise sequence \(\big\{\boldsymbol{\theta}_{exp}\big\}_{T}^{1:N} \sim \mathcal{N}(0,\boldsymbol{I})\) iteratively until \(t=0\), yielding the estimated final sequence \(\big\{\hat{\boldsymbol{\theta}}_{exp}\big\}^{1:N}\). These are then input to the frozen NPHM (Neural Parametric Head Model) model, utilizing facial smoothing, and mesh sequences are extracted using marching cubes.
BibTeX
If you find this work useful for your research, please consider citing:
@inproceedings{aneja2023facetalk,
author={Shivangi Aneja and Justus Thies and Angela Dai and Matthias Nießner},
title={FaceTalk: Audio-Driven Motion Diffusion for Neural Parametric Head Models},
booktitle = {Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},
year={2024},
}