Generalized Zero and Few-Shot Transfer for Facial Forgery Detection
1Visual Computing and AI Lab
Technical University of Munich
ABSTRACT
We propose Deep Distribution Transfer (DDT), a new transfer learning approach to address the problem of zero and few-shot transfer in the context of facial forgery detection. We examine how well a model (pre-)trained with one forgery creation method generalizes towards a previously unseen manipulation technique or different dataset. To facilitate this transfer, we introduce a new mixture model-based loss formulation that learns a multi-modal distribution, with modes corresponding to class categories of the underlying data of the source forgery method. Our core idea is to first pre-train an encoder neural network, which maps each mode of this distribution to the respective class labels, i.e., real or fake images in the source domain by minimizing wasserstein distance between them. In order to transfer this model to a new domain, we associate a few target samples with one of the previously trained modes. In addition, we propose a spatial mixup augmentation strategy that further helps generalization across domains. We find this learning strategy to be surprisingly effective at domain transfer compared to a traditional classification or even state-of-the-art domain adaptation/few-shot learning methods. For instance, compared to the best baseline, our method improves the classification accuracy by 4.88% for zero-shot and by 8.38% for the few-shot case transferred from the FaceForensics++ to Dessa dataset.
Method Overview
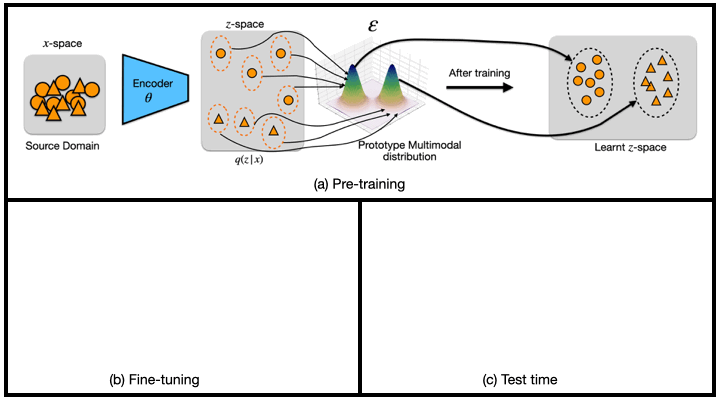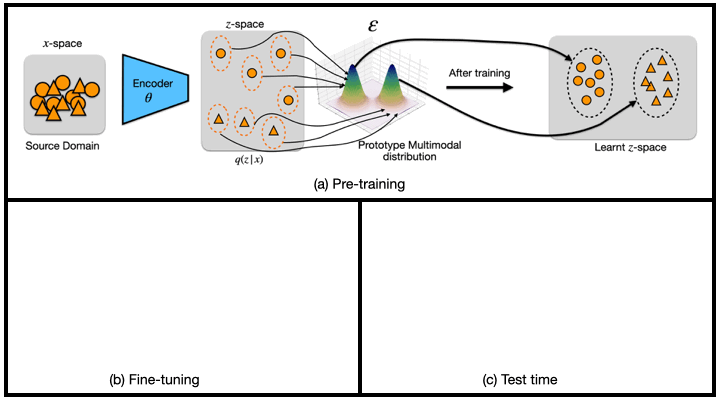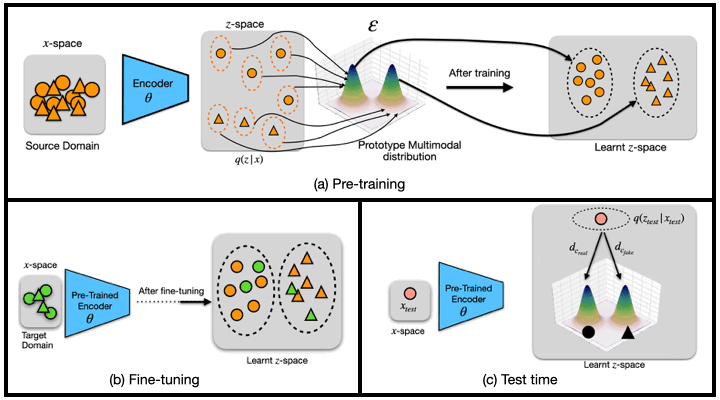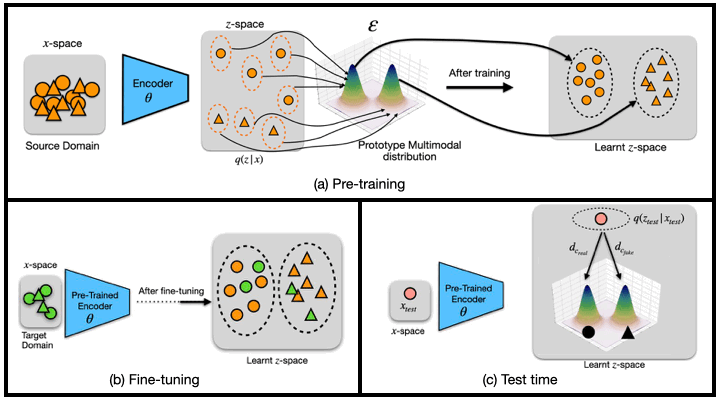
(a) Pre-training: $\theta$ encodes samples from the source domain into a latent distribution $q({z}_i|{x}_i)$. ${\epsilon}_c$ then maps class labels $c$ to the encoded distributions of the prototype multi-modal distribution ${\varepsilon}$.
(b) Fine-tuning: the pre-trained encoder ${\theta}$ is used to map the few-shot samples from the target dataset with the same prototype multi-modal distribution ${\varepsilon}$, which learns a common subspace between samples across domains.
(c) Test-time: a test sample ${x}_{test}$ is encoded into the latent distribution $q({z}_{test}|{x}_{test})$ by using the pre-trained encoder ${\theta}$. We then compute the distance of the latent code with respect to all components of the distribution, and assign a class label based on the component it is closest to.
DATASETS
Since our goal is to generalize across datasets and methods, we experimented on datasets with sufficient diversity. Please contact the corresponding authors to get access to the datasets. However, the AIF datasets is donated by AI Foundation to us and can be downloaded here
Figure shows sample frames from the datasets used for evaluation of our experiments. The top row shows the frames from the real videos and bottom row shows the frames from the corresponding fake videos for paired datasets (FaceForensics++ and Google DFD) and randomly selected videos for unpaired datasets (Dessa, AIF, and Celeb DF). For FaceForensics++, the frames from DF manipulation method are shown.




RESULTS
Zero-Shot Transfer
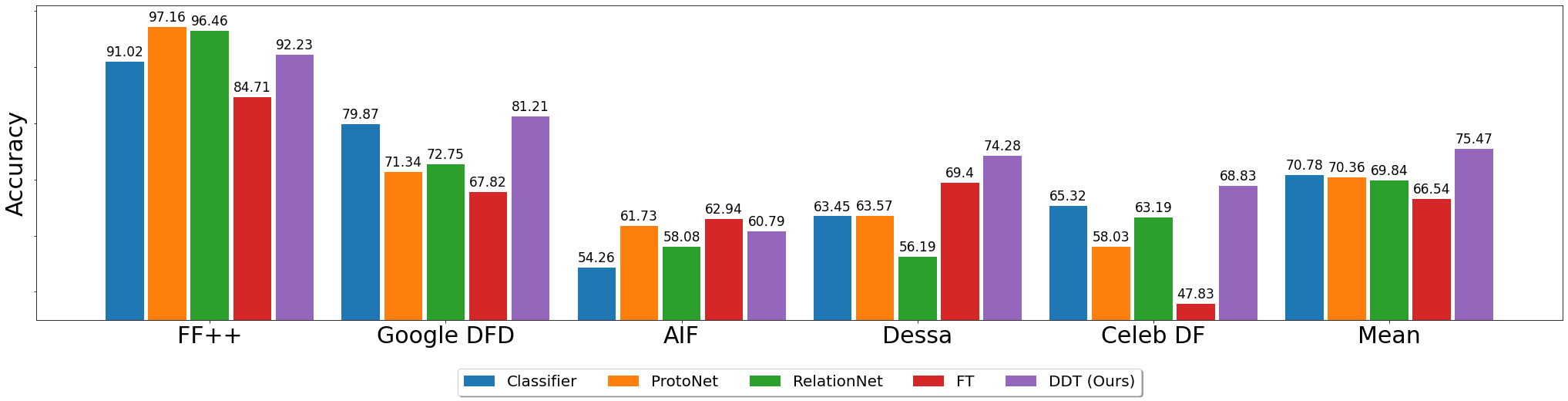
Zero-shot classification accuracy from FF++ to four other datasets: although there is a significant shift in domains (e.g., Google DFDC and Dessa contain mostly frontal faces in contrast to AIF which varies much more in pose and lightning), our method achieves transfer performance significantly higher than all baselines (last column).
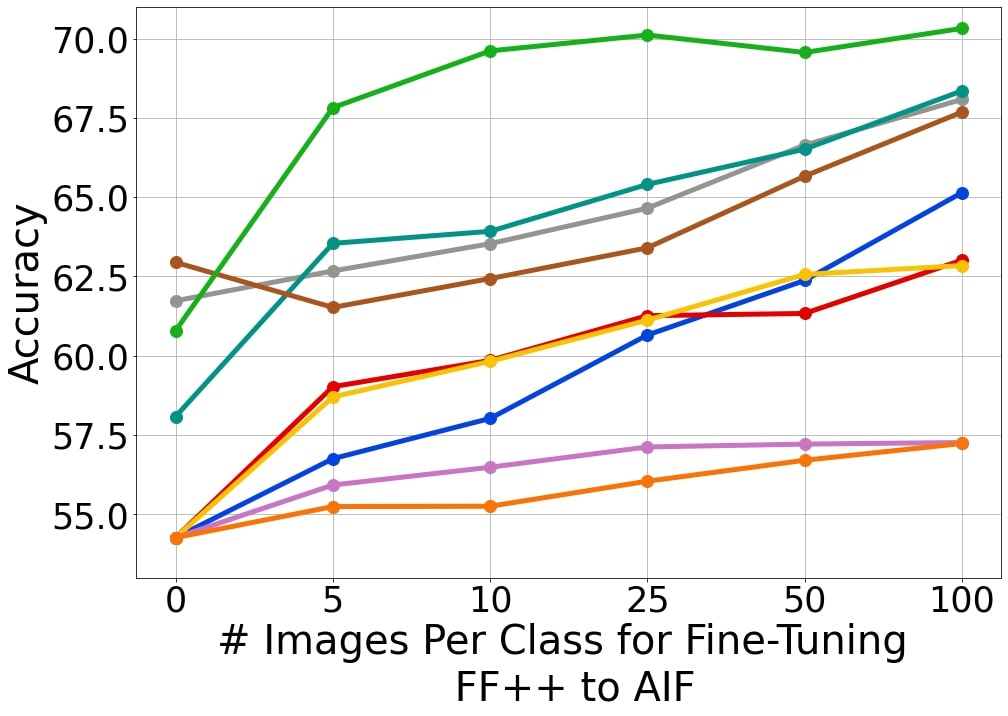
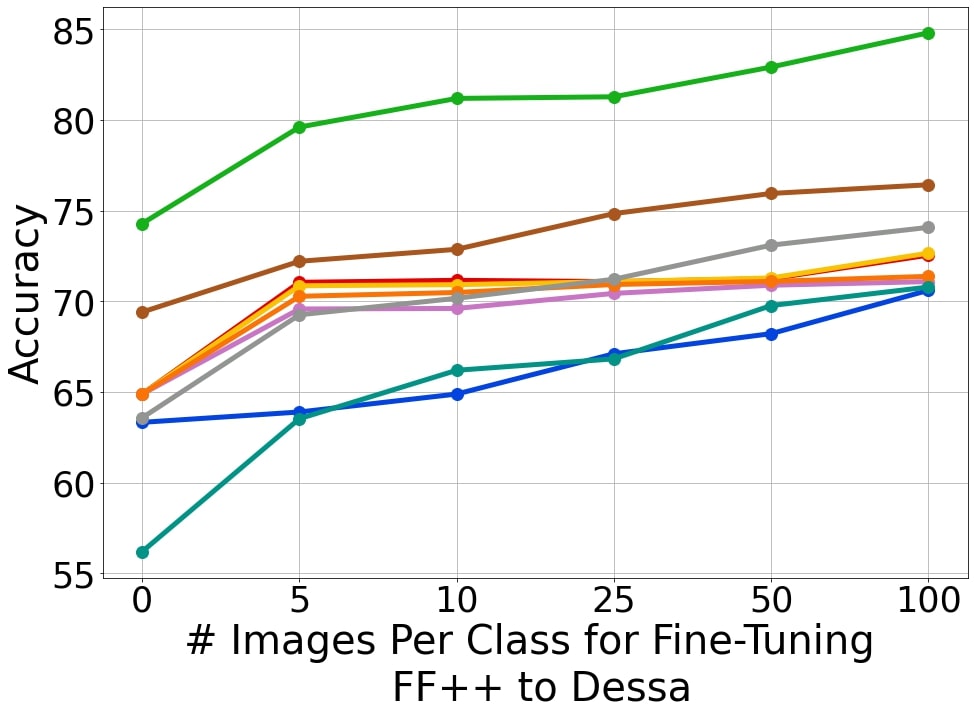
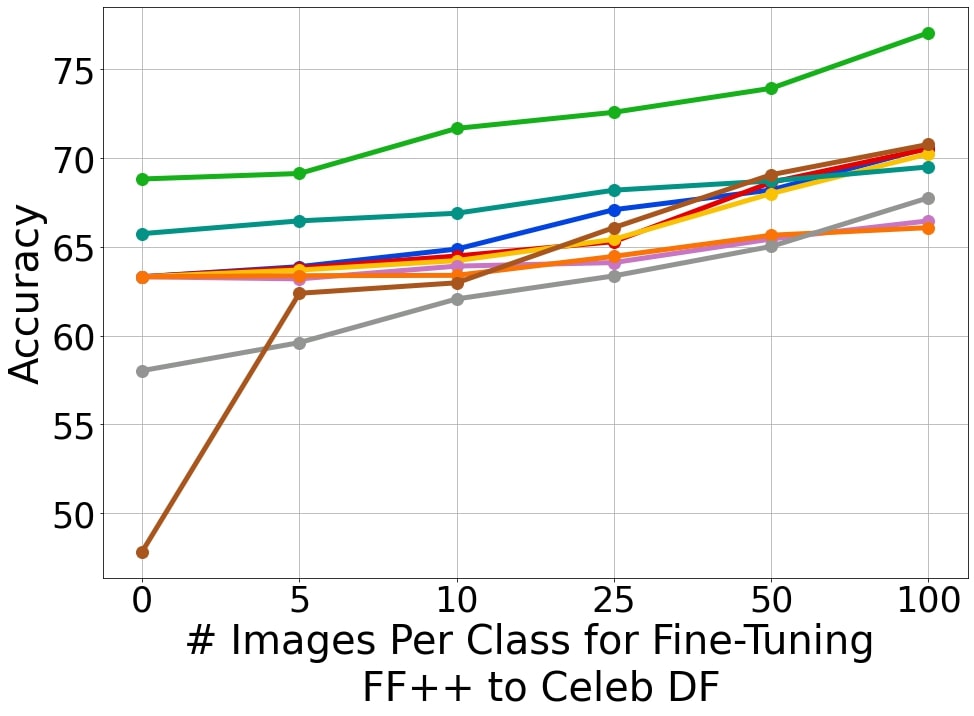
Few-Shot Transfer

BibTeX
If you find this work useful for your research, please consider citing:
@inproceedings{aneja2020generalized,
title={Generalized {Z}ero and {F}ew-{S}hot {T}ransfer for {F}acial {F}orgery {D}etection},
author={Shivangi Aneja and Matthias Nießner},
booktitle={ArXiv preprint arXiv:2006.11863},
year={2020}}