COSMOS: Catching Out-of-Context Misinformation with Self-Supervised Learning
1Technical University of Munich
2Google AI
COSMOS: Concept Figure

Our method takes as input an image and two captions from different sources, and we predict whether the image has been used out of context or not. We show that it is critical to the task to ground the captions w.r.t. image, and it is insufficient to consider only the captions; e.g., a language-only model would incorrectly classify the right image to be out of context. To this end, we propose a new self-supervised learning strategy allowing to make fairly accurate out-of-context predictions.
ABSTRACT
Despite the recent attention to DeepFakes, one of the most prevalent ways to mislead audiences on social media is the use of unaltered images in a new but false context. To address these challenges and support fact-checkers, we propose a new method that automatically detects out-of-context image and text pairs. Our key insight is to leverage grounding of image with text to distinguish out-of-context scenarios that cannot be disambiguated with language alone. We propose a self-supervised training strategy where we only need a set of captioned images. At train time, our method learns to selectively align individual objects in an image with textual claims, without explicit supervision. At test time, we check if both captions correspond to same object(s) in the image but are semantically different, which allows us to make fairly accurate out-of-context predictions. Our method achieves 85% detection accuracy ouperforming language only baseline. To facilitate benchmarking of this task, we create a large-scale dataset of 200K images with 450K textual captions from a variety of news websites, blogs, and social media posts.

VIDEO
Dataset Details
We obtained our images primarily from news channels (New York Times, CNN, Reuters, ABC, PBS, NBCLA, AP News, Sky News, Telegraph, Time, DenverPost, Washington Post, CBC News, Guardian, Herald Sun, Independent, CS Gazette, BBC) and fact-checking website Snopes. We scraped images from a wide-variety of articles, with special focus on topics where misinformation spread is prominent, as shown in the figure below. We created a large dataset of 200K images that are matched with 450K textual captions from a variety of news websites, blogs, and social media posts.
Category-Wise Frequency Distribution of the Dataset
Results
Qualitative Results


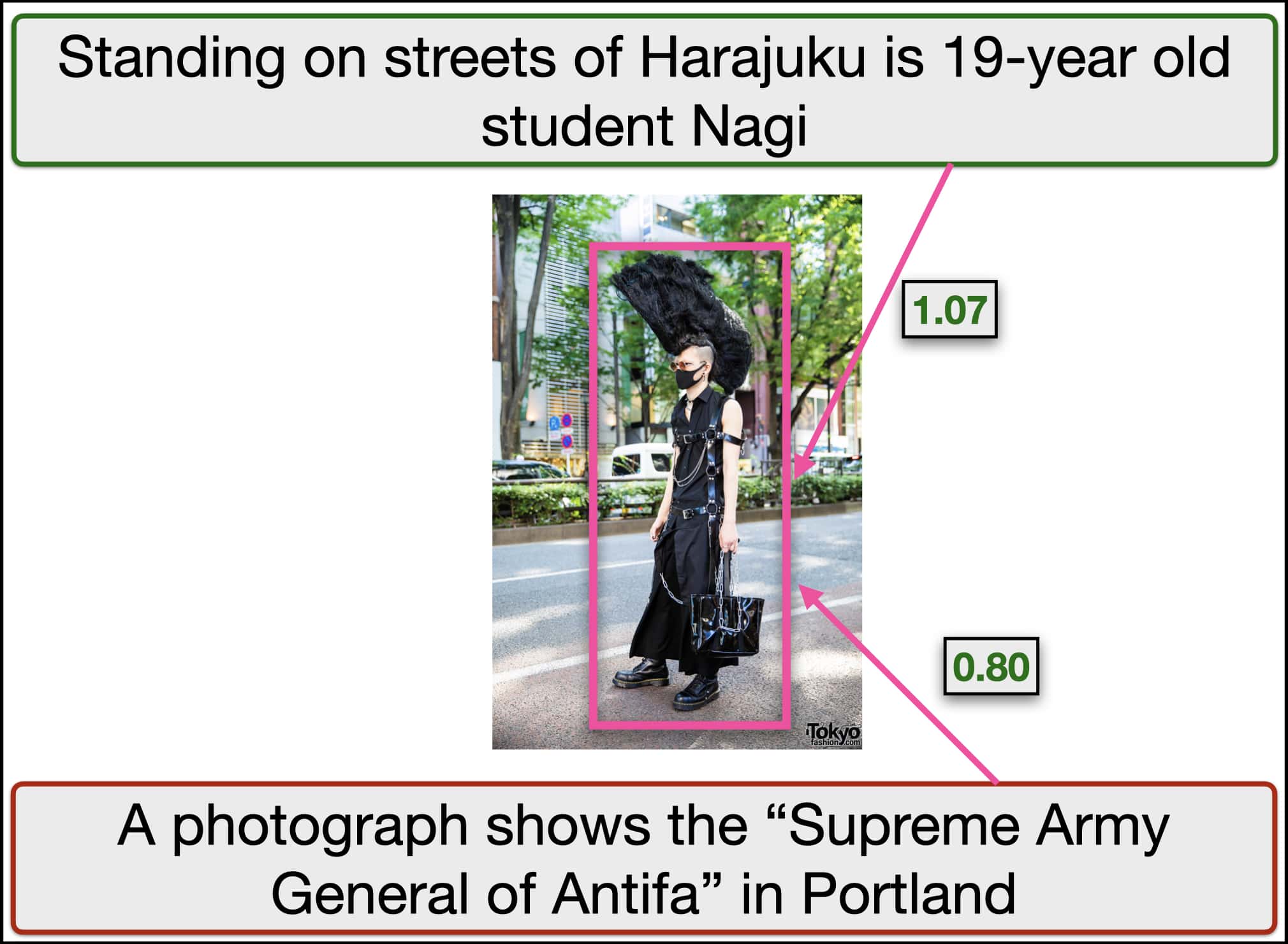



Qualitative results showing visual grounding of captions with the objects in the image. The top row show the grounding for out-of-context pairs and the bottom row show the grounding for pairs which are not out-of-context. We show object-caption scores for two captions per image. The captions with green border show the true captions and the captions with red border show the false caption. Scores indicate association of the most relevant object in the image with the caption.
Comparison with alternate baselines
We compare our method against several rumor and fake news detection methods. Our method outperforms all other methods, resulting in 85% out-of-context detection accuracy. Please refer to our paper for more details.
BibTeX
If you find this work useful for your research, please consider citing:
@inproceedings{aneja2021cosmos,
title={{COSMOS}: Catching {O}ut-of-{C}ontext {M}isinformation with {S}elf-{S}upervised {L}earning},
author={Shivangi Aneja and Chris Bregler and Matthias Nie{\ss}ner},
booktitle={ArXiv preprint arXiv:2101.06278},
year={2021}
}